Azure monitoring beyond
Azure Monitor.
Azure Monitor gives you metrics. Applicare gives you causality — correlating VMs, AKS, SQL, Blob, Functions, and 30+ Azure services into a unified entity graph.
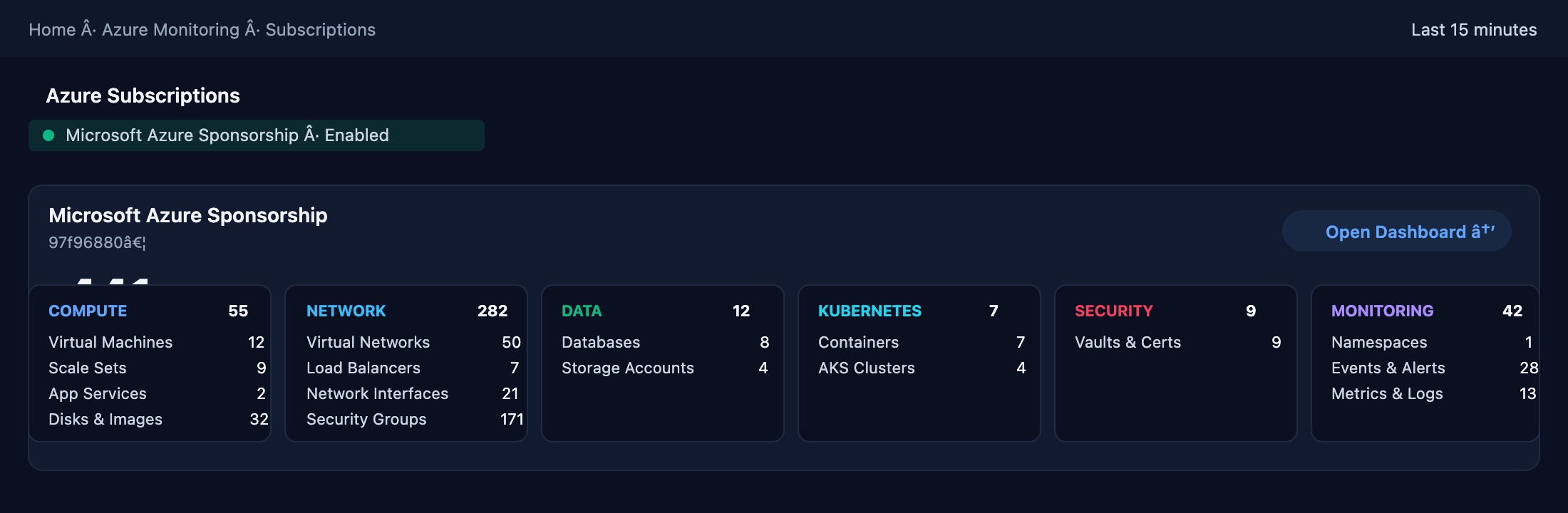
Azure Monitoring — deeper than native tools.
See Applicare in Action
Every Azure resource — compute, network, storage, databases, Kubernetes, and applications — monitored in a single pane of glass.
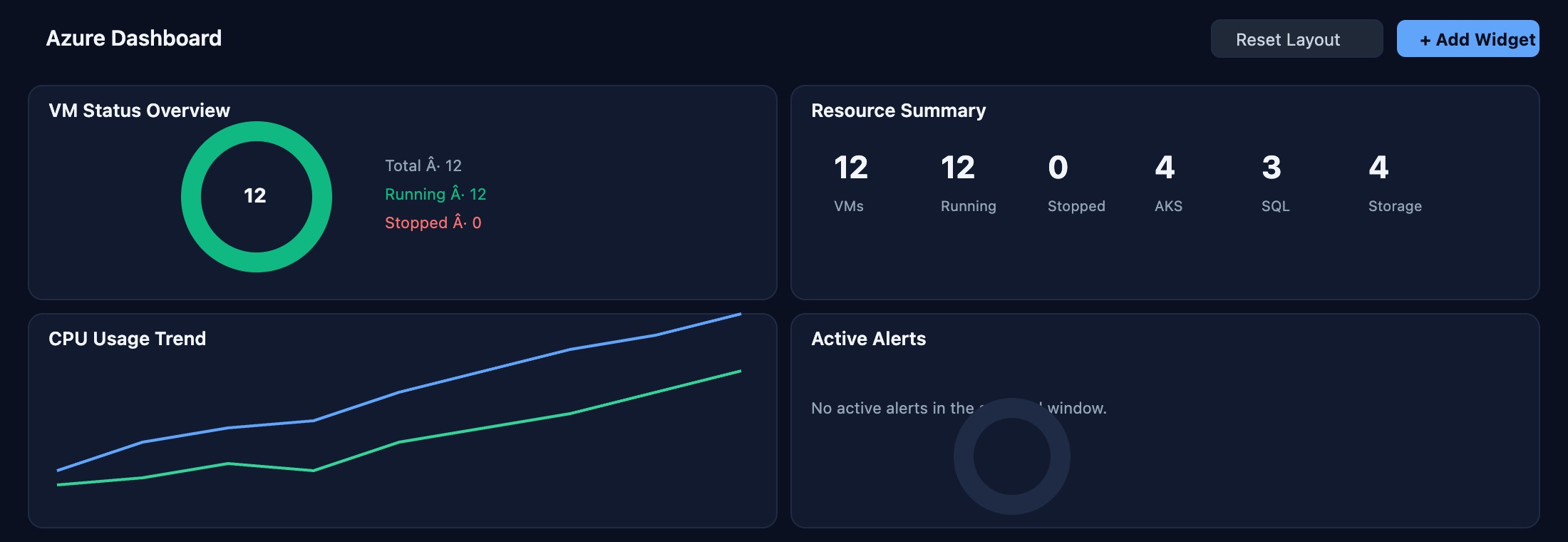
Azure Dashboard
Unified command center showing all 12 VMs running across your Azure subscription, with real-time health scores, resource utilization, and anomaly indicators surfaced by IntelliSense AI.
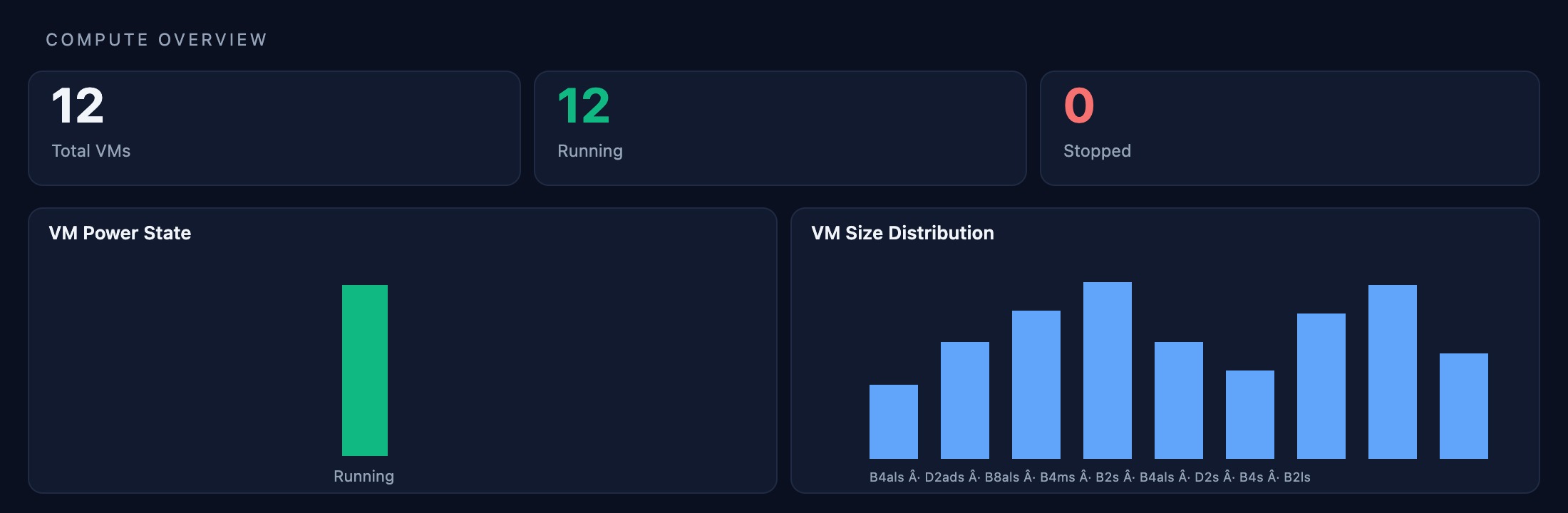
Compute — Virtual Machines
Live view of all 12 VMs: CPU, memory, disk I/O, and network per instance. Applicare correlates VM-level metrics with application performance to pinpoint noisy neighbors and over-provisioned resources.

Network Topology
254 network resources mapped in one view — 171 NSG flow logs, 50 VNets, 3 Application Gateways, and 4 Load Balancers. Applicare traces latency spikes to specific hops and identifies misconfigured security rules automatically.
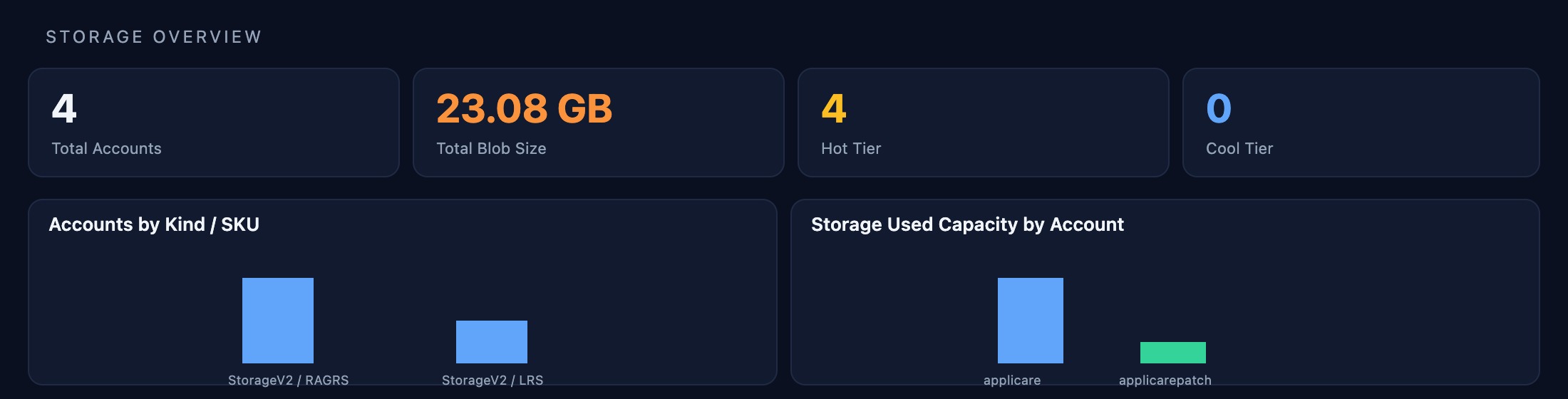
Storage Accounts
Four storage accounts totalling 23.08 GB monitored for throughput, availability, and anomalous access patterns. The applicare account (21.84 GB) is tracked with per-container drill-down and cost attribution.
Azure SQL & Managed Databases
Three databases in view: applicaresql (Paused), globex_erp (Online), and master (Online). Applicare tracks query latency, DTU consumption, deadlocks, and long-running transactions with automatic root-cause tagging.
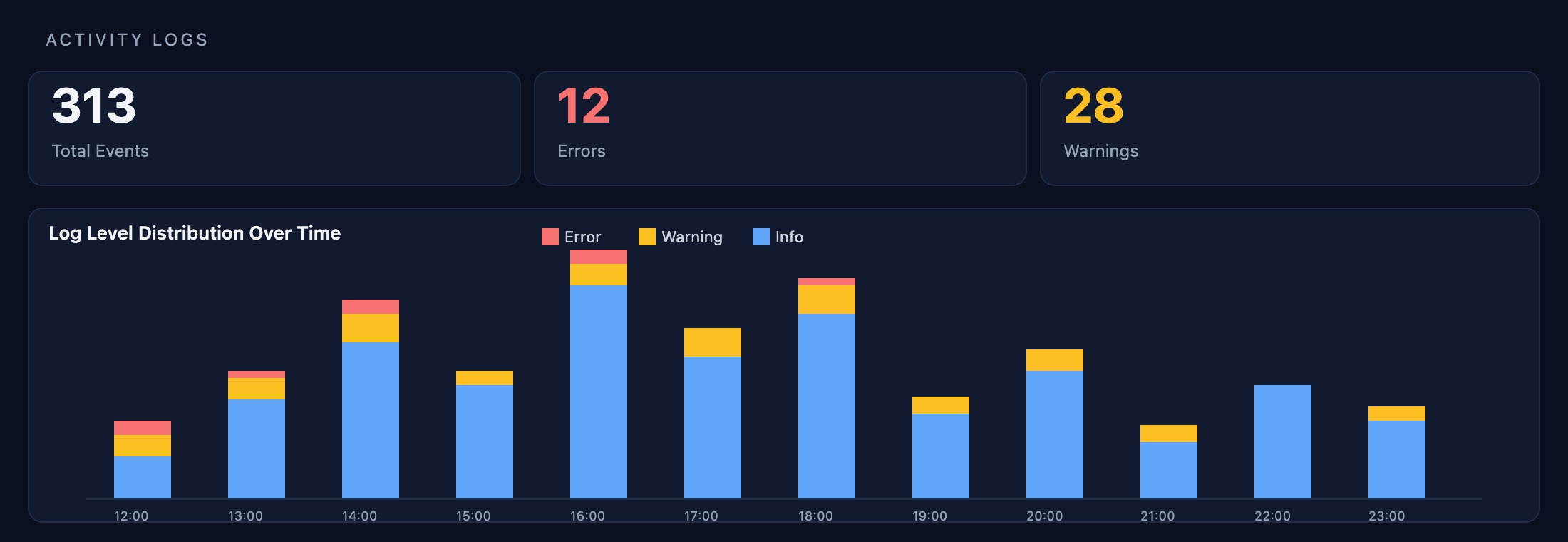
Alerts & Metrics
50 monitored resources, 12 metric alert rules, and 18 Prometheus rule groups — all in one pane. Applicare suppresses noise with AI-driven alert correlation so your team acts on incidents, not symptoms.
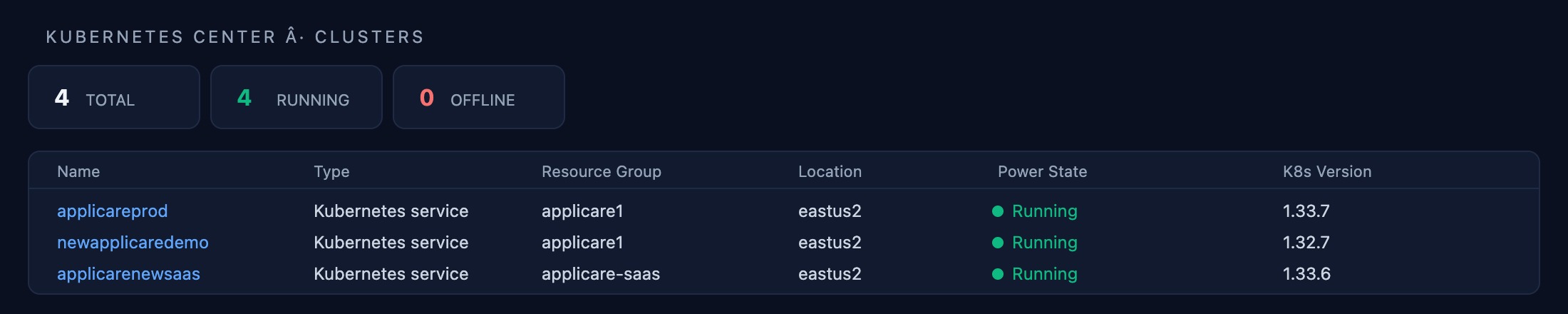
Kubernetes — Cluster Overview
Four AKS clusters tracked end-to-end: newapplicaredemo (1.32.7) and three clusters on 1.33.7. Node health, pod scheduling failures, and control-plane latency are surfaced before they cascade into outages.
Kubernetes — Workload Deep Dive
Per-namespace resource consumption, pod restart storms, OOMKill events, and HPA scaling history — all correlated with application response times so you know exactly which workload is causing user impact.
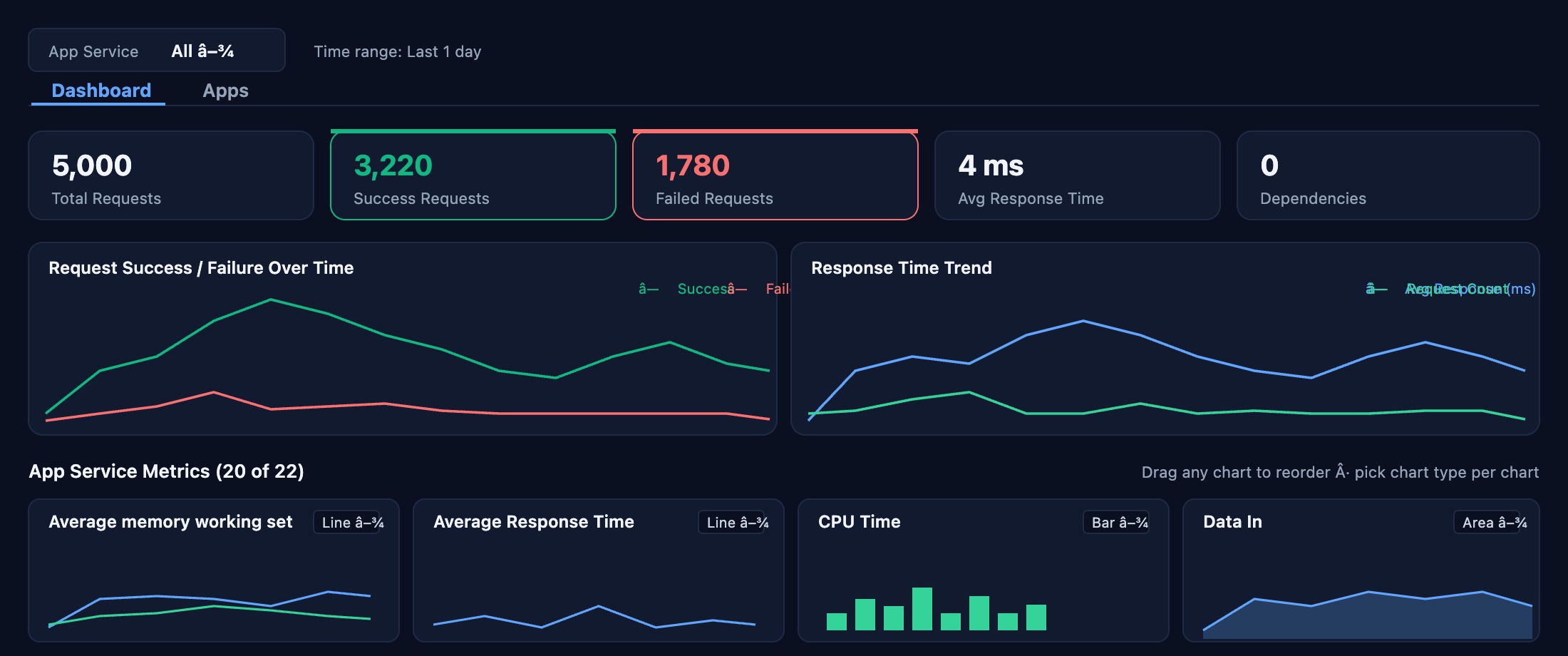
App Services Performance
5,000 requests tracked: 3,220 successful, 1,780 failed, 4 ms average response. Applicare maps HTTP errors to deployment events, dependency failures, and infrastructure changes without manual correlation.
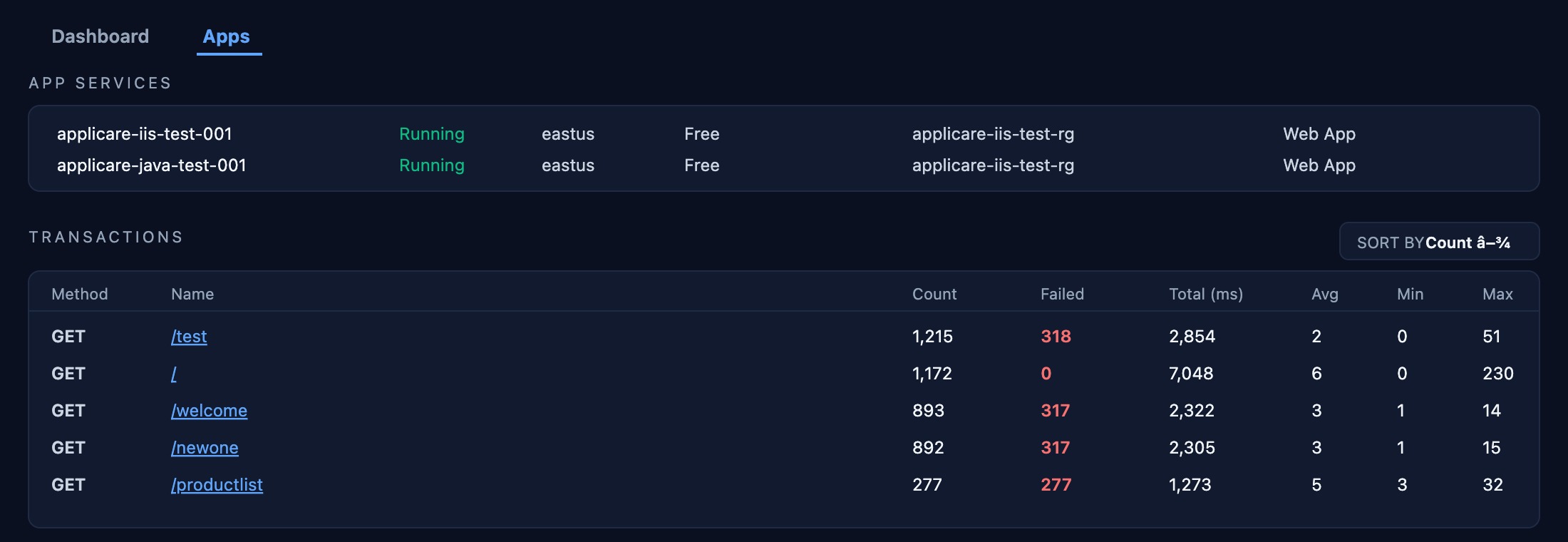
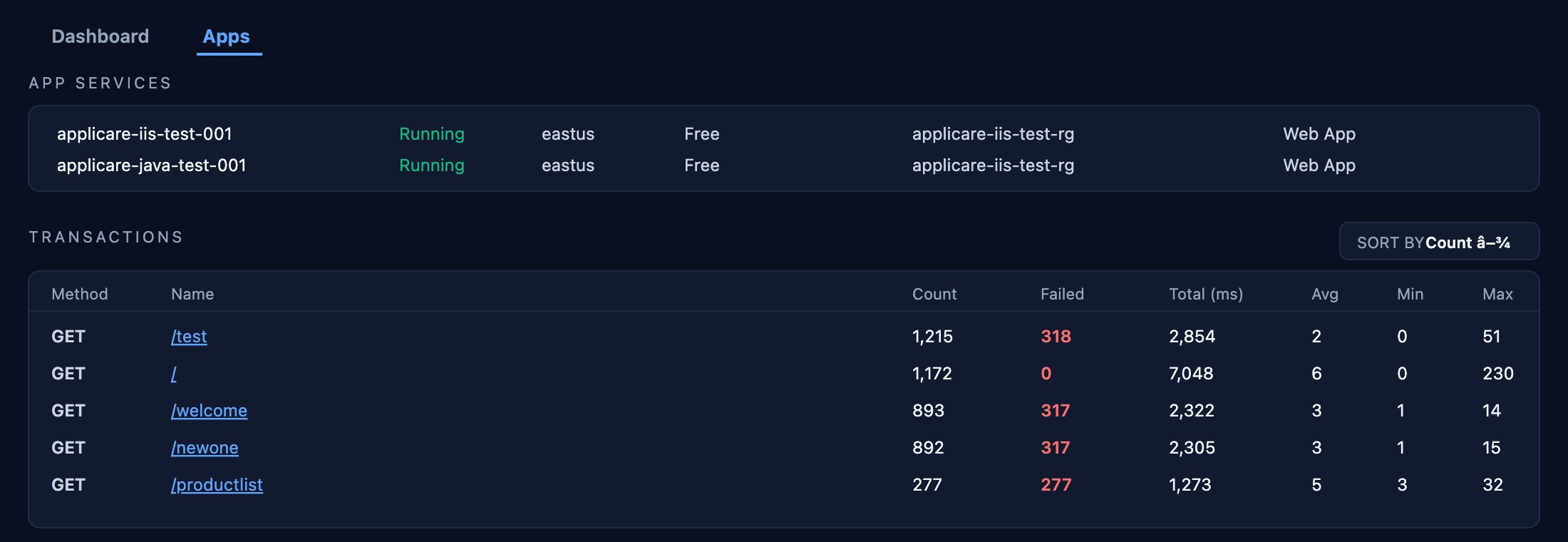
Transaction Tracing
End-to-end tracing for every API call — GET /test shows 1,215 calls, 318 failures, 2 ms average. Identify slow downstream dependencies, retry storms, and payload anomalies at the individual transaction level.